AI야 공부하랬더니 왜 키보드만 때리니? - 보상이냐 패널티냐, 그것이 문제로다
안녕하세요! 오늘은 제가 최근에 도전했던 조금 특별한 프로젝트, 리듬 게임을 마스터하는 AI(Only4BMS) 개발기를 들려드리려고 합니다.
요즘 어딜 가나 LLM이니 생성형 AI(Generative AI)니 하는 이야기들이 대세죠? 하지만 저는 문득 예전 알파고(AlphaGo) 시절의 뜨거웠던 ‘강화학습’ 유행이 다시 생각나더라고요. 정해진 답을 내놓는 게 아니라, 스스로 시행착오를 겪으며 최적의 길을 찾아가는 그 모습이 참 매력적이었거든요.
파이썬 개발자로 살면서 강화학습(Reinforcement Learning)은 늘 궁금했지만, 막상 “뭘 만들어볼까?” 고민하면 막막했는데요. 그러다 문득 “내가 못 깨는 리듬 게임 곡을 AI는 깰 수 있을까?” 하는 궁금증에서 이 무모한 도전이 시작되었습니다.
1. AI에게 리듬을 가르치는 방법: PPO와 RhythmEnv
우선 AI가 리듬 게임 세상을 이해할 수 있는 ‘환경’을 만들어줘야 했습니다.
- 알고리즘:
stable-baselines3의 PPO(Proximal Policy Optimization)를 사용했습니다. - 환경 표준(Gymnasium): 본격적인 구현에는
import gymnasium as gym을 사용했습니다. 강화학습 하면 떠오르는 OpenAI Gym의 뒤를 잇는 표준 라이브러리죠. - Gymnasium의 유래와 근황: OpenAI가 Gym의 유지보수에서 손을 뗀 후, 현재는 Farama Foundation에서 관리하고 있습니다. 하위 호환성을 유지하면서도 API를 더 깔끔하게 다듬어(예: truncated 신호 추가 등) 현재는 강화학습 프로젝트의 표준으로 자리 잡았습니다.
- 커스텀 환경(RhythmEnv): Gymnasium의
gym.Env를 상속받아 4라인 리듬 게임 환경을 직접 구축했습니다.observation_space로 게임의 상태를 정의하고,action_space로 AI의 행동 범위를 설정하는 방식이죠. - 액션: 0(가만히 있기), 1(키 누르기) 딱 두 가지입니다.
- 시간 해상도: 16ms(~60 FPS) 간격으로 AI가 판단을 내리도록 설계했습니다. 인간의 반응 속도보다 훨씬 빠른 극한의 환경이죠!
2. 강화학습의 함정: “사탕만 뺏어가는 아이” vs “혼날까 봐 입 꾹 닫은 학생”
이번 프로젝트에서 가장 인상 깊었던 건 기술적인 코드보다 ‘보상(Reward) 설계’였습니다. AI는 정말 우리가 원하는 대로 움직이는 게 아니라, 우리가 설정한 보상 시스템의 빈틈을 기막히게 찾아내더라고요.
연타 빌런 (The Ghosting Villain)
처음에는 “노트를 맞추면 보상을 주자!”는 생각에 보상을 후하게 줬습니다. 그랬더니 AI가 수능 공부는 안 하고 사탕만 뺏어 가려는 아이처럼 변해버렸습니다. 수업 시간 내내 키보드를 미친 듯이 연타(Ghosting)하기 시작한 거죠. 어차피 많이 누르다 보면 몇 개는 맞을 테고, 그럼 보상을 받으니까요!
무저항 주의 AI (The Silent Stoic)
“그래? 그럼 아무 때나 누르면 엄청난 패널티를 주겠어!” 패널티를 대폭 높였더니, 이번엔 AI가 “말 한마디 잘못했다가 혼나는 게 무서워서 질문에 대답조차 안 하는 학생”이 되었습니다. 틀려서 마이너스 점수를 받는 게 너무 무서운 나머지, 아예 키보드에서 손을 떼고 가만히 ‘서바이벌 보상’만 챙기며 버티기만 하더군요.
결국 보상(Perfect Hit +10.0)과 패널티(Random Press -1.0) 사이의 정교한 줄타기가 필요했습니다. 이 균형을 맞추는 과정이 마치 리듬 게임의 손맛을 조율하는 마스터링 작업처럼 느껴졌어요.
3. ‘인간다운’ AI 만들기: Perception Jitter
AI가 너무 완벽해도 재미없죠? (사실 너무 완벽하면 핵 쓰는 기분이랄까요…) 그래서 Perception Jitter라는 개념을 도입했습니다. AI의 인식에 아주 미세한 오차를 주는 거죠.
- model_hard: 지터 2ms. 거의 기계적인 완벽함을 보여줍니다.
- model_normal: 지터 30ms. 인간적인 실수를 적당히 섞어가며 연주합니다.
이 지터 값을 조절하면서 AI에게 ‘성격’을 부여하는 과정이 정말 흥미로웠습니다.
4. 첫 강화학습 도전을 마치며
강화학습을 처음 구현해보며 깨달은 점은 명확합니다. “AI는 우리가 시킨 대로가 아니라, 우리가 준 보상 체계의 최적점을 찾아간다”는 사실이죠.
실제로 제가 만든 AI가 게임을 플레이하는 영상은 아래에서 보실 수 있습니다! 제법 그럴싸하게 플레이하죠? 영상의 왼쪽은 사람(저입니다..)이고, 오른쪽은 강화학습 AI(Normal 버전)예요.
Normal 버전은 인간적인 느낌을 주려고 일부러 노이즈(Jitter)를 강하게 섞었더니, 리듬 게임 초보자분들도 큰 부담 없이 즐겁게 구경하실 수 있을 만한 실력이 되었답니다.
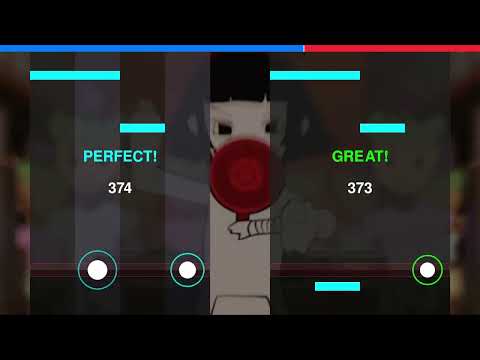
비록 처음엔 키보드만 때려 부수던(?) AI였지만, 이제는 model_hard와 model_normal이라는 늠름한 결과물로 탄생했습니다.
이 프로젝트의 전체 소스 코드와 환경 설정이 궁금하시다면 제 GitHub 저장소를 방문해 주세요. 스타(Star)와 피드백은 언제나 환영입니다!
처음 강화학습에 도전하시는 분들이라면, 알고리즘 공부만큼이나 ‘보상 시스템 설계’에 공을 들여보세요. 그 과정에서 AI와 밀당하는 색다른 재미를 느끼실 수 있을 겁니다!
그럼 저는 다음 개발기로 찾아오겠습니다. 다들 즐거운 코딩 하세요!
Behind the Scenes: 이번 프로젝트는 주말 동안 이른바 ‘바이브 코딩(Vibe Coding)’으로 신나게 달려보았습니다. 그리고 지금, 일요일 저녁에 지난 이틀간의 개발 성과를 제미나이(Gemini)와 함께 깔끔하게 요약해서 블로그 포스팅까지 마쳤네요. AI와 함께하니 개발부터 기록까지 한 호흡에 끝낼 수 있어 정말 뿌듯한 주말입니다!